Pandas Introduction 5
vectorized string operation
capitalize
It needs for loop to realize the capitalization.
1 | import numpy as np |
but it can’t be used with None types:
1 | data = ['peter', 'Paul', None, 'MARY', 'gUIDO'] [s.capitalize() for s in data] |
another way:
1 | #make the array to DataFrame |
other functions in pandas.str:
len() lower() translate() islower()
ljust() upper() startswith() isupper()
rjust() find() endswith() isnumeric()
center() rfifind() isalnum() isdecimal()
zfifill() index() isalpha() split()
strip() rindex() isdigit() rsplit()
rstrip() capitalize() isspace() partition()
lstrip() swapcase() istitle() rpartition()
they are similar to those in python
comparison
| 方法 | 描述 |
|---|---|
| match() | 对每个元素调用 re.match(),返回布尔类型值 |
| extract() | 对每个元素调用 re.match(),返回匹配的字符串组(groups) |
| findall() | 对每个元素调用 re.findall() |
| replace() | 用正则模式替换字符串 |
| contains() | 对每个元素调用 re.search(),返回布尔类型值 |
| count() | 计算符合正则模式的字符串的数量 |
| split() | 等价于 str.split(),支持正则表达式 |
| rsplit() | 等价于 str.rsplit(),支持正则表达式 |
1 | monte = pd.Series(['Graham Chapman', 'John Cleese', 'Terry Gilliam', |
others:
| 方法 | 描述 |
|---|---|
| get() | 获取元素索引位置上的值,索引从 0 开始 |
| slice() | 对元素进行切片取值 |
| slice_replace() | 对元素进行切片替换 |
| cat() | 连接字符串(此功能比较复杂,建议阅读文档) |
| repeat() | 重复元素 |
| normalize() | 将字符串转换为 Unicode 规范形式 |
| pad() | 在字符串的左边、右边或两边增加空格 |
| wrap() | 将字符串按照指定的宽度换行 |
| join() | 用分隔符连接 Series 的每个元素 |
| get_dummies() | 按照分隔符提取每个元素的 dummy 变量,转换为独热(one-hot)编码的 DataFrame |
df.str.slice(0, 3) = df.str[0:3]
1 | monte.str[0:3] |
get_dummies()
1 | full_monte = pd.DataFrame({'name': monte, |
time
the format of time
1 | from datetime import datetime |
show what day is today
1 | date.strftime('%A') #%A is the special code for this function |
calculate with numpy:
1 | import numpy as np |
1 | date + np.arange(12) |
when it comes to minute:
1 | np.datetime64('2015-07-04 12:00') |
the last digit can be changed:
1 | np.datetime64('2015-07-04 12:59:59.50', 'ns') |
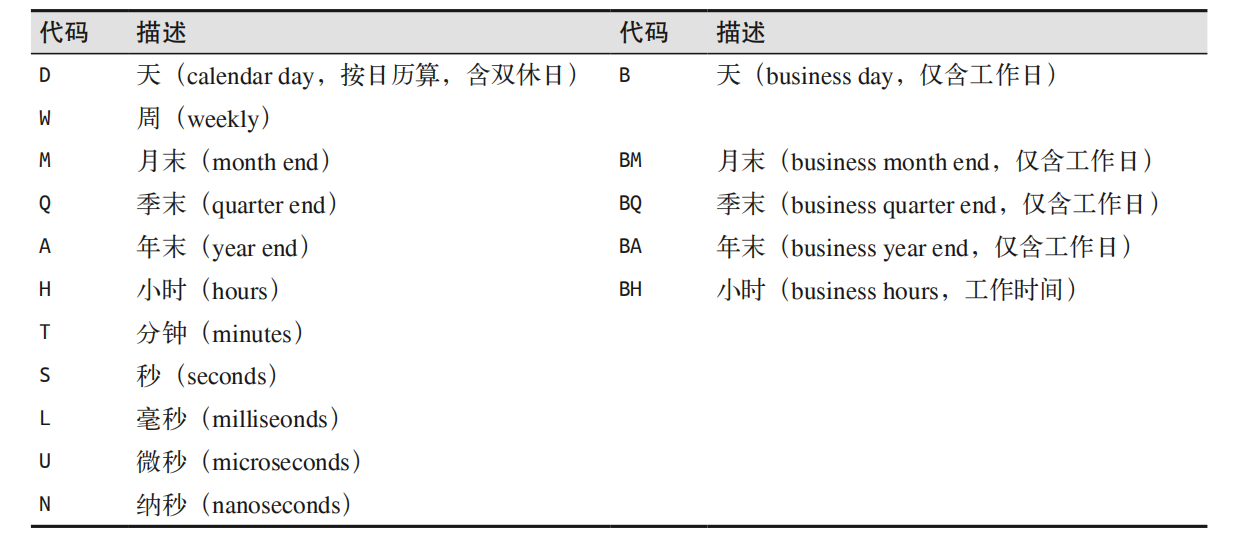
| 代码 | 含义 | 时间跨度 (相对) | 时间跨度 (绝对) |
|---|---|---|---|
| Y | 年(year) | ± 9.2e18 年 | [9.2e18 BC, 9.2e18 AD] |
| M | 月(month) | 7.6e17 年 | ±[7.6e17 BC, 7.6e17 AD] |
| W | 周(week) | ± 1.7e17 年 | [1.7e17 BC, 1.7e17 AD] |
| D | 日(day) | ± 2.5e16 年 | [2.5e16 BC, 2.5e16 AD] |
| h | 时(hour) | ± 1.0e15 年 | [1.0e15 BC, 1.0e15 AD] |
| m | 分(minute) | ± 1.7e13 年 | [1.7e13 BC, 1.7e13 AD] |
| s | 秒(second) | ± 2.9e12 年 | [ 2.9e9 BC, 2.9e9 AD] |
| ms | 毫秒(millisecond) | ± 2.9e9 年 | [ 2.9e6 BC, 2.9e6 AD] |
| us | 微秒(microsecond) | ± 2.9e6 年 | [290301 BC, 294241 AD] |
| ns | 纳秒(nanosecond) | ± 292 年 | [ 1678 AD, 2262 AD] |
| ps | 皮秒(picosecond) | ± 106 天 | [ 1969 AD, 1970 AD] |
| fs | 飞秒(femtosecond) | ± 2.6 小时 | [ 1969 AD, 1970 AD] |
| as | 原秒(attosecond) | ± 9.2 秒 | [ 1969 AD, 1970 AD] |
use time as index
timestamp
1 | index = pd.DatetimeIndex(['2014-07-04', '2014-08-04', '2015-07-04', '2015-08-04']) |
pd.datetime() can change different format of time into one:
1 | dates = pd.to_datetime([datetime(2015, 7, 3), '4th of July, 2015', |
period
1 | dates.to_period('D') |
delta
1 | dates - dates[0] |
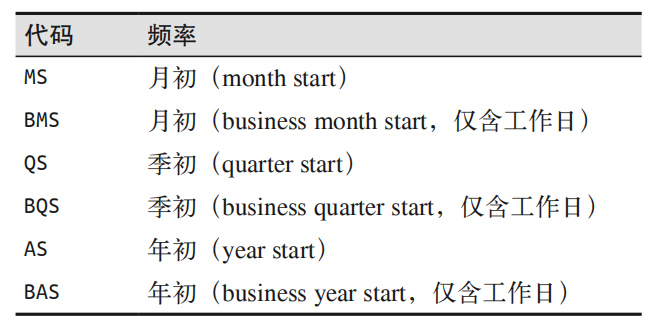
pd.date_range(): show the time in order
1 | pd.date_range('2015-07-03', '2015-07-10') |
use freq to change the difference between time points
1 | pd.date_range('2015-07-03', periods=8, freq='H') |
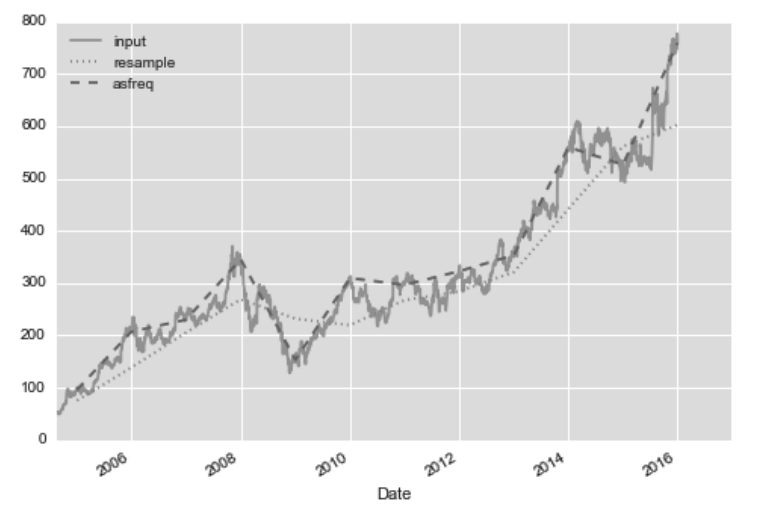
resample
1 | goog.plot(alpha=0.5, style='-') |
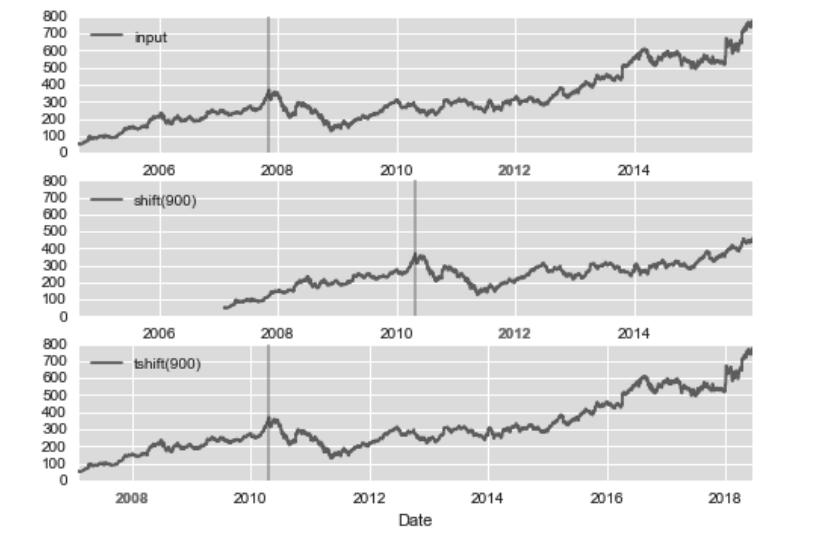
shift() and tshift()
make the value shift 900 days:
pandas.eval()
faster to calculate
(1) 算术运算符。
1 | result1 = -df1 * df2 / (df3 + df4) - df5 |
(2) 比较运算符。
1 | result1 = (df1 < df2) & (df2 <= df3) & (df3 != df4) |
(3) 位运算符。
1 | result1 = (df1 < 0.5) & (df2 < 0.5) | (df3 < df4) |
1 | result3 = pd.eval('(df1 < 0.5) and (df2 < 0.5) or (df3 < df4)') |
(4) 对象属性与索引。
1 | result1 = df2.T[0] + df3.iloc[1] |
query:
1 | result1 = df[(df.A < 0.5) & (df.B < 0.5)] |
1 | Cmean = df['C'].mean() |