05.1.Read annotations from JSON file
Import packages
1 | # -*- coding: UTF-8 -*- |
Open JSON file
1 | with open('./dataset/resizedFullGarbageDataset/train.json', 'r', encoding='utf-8') as f: |
Observe the data format
1 | train_labels #observe the types of the data |
1 | out:{'info': None, |
1 | type(train_labels) #find the tye of the labels |
1 | train_labels.keys() |
Read categories
1 | train_labels['categories'] #print the categories |
1 | out:[{'id': 1, 'name': '瓜子壳'}, |
1 | type(train_labels['categories']) |
1 | train_labels['categories'][0]#choose the first one |
Convert to list in order to use easier. (Attention: id begins at 1, while the index of list begins at 0)
1 | names = [] |
#out:[‘瓜子壳’, ‘核桃’, ‘花生壳’, ‘毛豆壳’, ‘西瓜子’, ‘枣核’, ‘话梅核’, ‘苹果皮’, ‘柿子皮’, ‘西瓜皮’, ‘香蕉皮’, ‘柚子皮’, ‘荔枝壳’, ‘芒果皮’, ‘苹果核’, ‘干果’, ‘桔子皮’, ‘饼干’, ‘面包’, ‘糖果’, ‘宠物饲料’, ‘风干食品’, ‘蜜饯’, ‘肉干’, ‘冲泡饮料粉’, ‘奶酪’, ‘罐头’, ‘糕饼’, ‘薯片’, ‘树叶’, ‘杂草’, ‘绿植’, ‘鲜花’, ‘豆类’, ‘动物内脏’, ‘绿豆饭’, ‘谷类及加工物’, ‘贝类去硬壳’, ‘虾’, ‘面食’, ‘肉类’, ‘五谷杂粮’, ‘排骨-小肋排’, ‘鸡’, ‘鸡骨头’, ‘螺蛳’, ‘鸭’, ‘鱼’, ‘菜根’, ‘菜叶’, ‘菌菇类’, ‘鱼鳞’, ‘调料’, ‘茶叶渣’, ‘咖啡渣’, ‘粽子’, ‘动物蹄’, ‘小龙虾’, ‘蟹壳’, ‘酱料’, ‘鱼骨头’, ‘蛋壳’, ‘中药材’, ‘中药渣’, ‘镜子’, ‘玻璃制品’, ‘窗玻璃’, ‘碎玻璃片’, ‘化妆品玻璃瓶’, ‘食品及日用品玻璃瓶罐’, ‘保温杯’, ‘玻璃杯’, ‘图书期刊’, ‘报纸’, ‘食品外包装盒’, ‘鞋盒’, ‘利乐包’, ‘广告单’, ‘打印纸’, ‘购物纸袋’, ‘日历’, ‘快递纸袋’, ‘信封’, ‘烟盒’, ‘易拉罐’, ‘金属制品’, ‘吸铁石’, ‘铝制品’, ‘金属瓶罐’, ‘金属工具’, ‘罐头盒’, ‘勺子’, ‘菜刀’, ‘叉子’, ‘锅’, ‘金属筷子’, ‘数据线’, ‘塑料玩具’, ‘矿泉水瓶’, ‘塑料泡沫’, ‘塑料包装’, ‘硬塑料’, ‘一次性塑料餐盒餐具’, ‘电线’, ‘塑料衣架’, ‘密胺餐具’, ‘亚克力板’, ‘PVC管’, ‘插座’, ‘化妆品塑料瓶’, ‘篮球’, ‘足球’, ‘KT板’, ‘食品塑料盒’, ‘食用油桶’, ‘塑料杯’, ‘塑料盆’, ‘一次性餐盒’, ‘废弃衣服’, ‘鞋’, ‘碎布’, ‘书包’, ‘床上用品’, ‘棉被’, ‘丝绸手绢’, ‘枕头’, ‘毛绒玩具’, ‘皮带’, ‘电路板’, ‘充电宝’, ‘木制品’, ‘优盘’, ‘灯管灯泡’, ‘节能灯’, ‘二极管’, ‘纽扣电池’, ‘手机电池’, ‘镍镉电池’, ‘锂电池’, ‘蓄电池’, ‘胶卷’, ‘照片’, ‘指甲油瓶’, ‘X光片’, ‘农药瓶’, ‘杀虫剂及罐’, ‘蜡烛’, ‘墨盒’, ‘染发剂壳’, ‘消毒液瓶’, ‘油漆桶’, ‘药品包装’, ‘药瓶’, ‘废弃针管’, ‘输液管’, ‘口服液瓶’, ‘眼药水瓶’, ‘水银温度计’, ‘水银血压计’, ‘胶囊’, ‘药片’, ‘固体杀虫剂’, ‘甘蔗皮’, ‘坚果壳’, ‘橡皮泥’, ‘毛发’, ‘棉签’, ‘创可贴’, ‘口红’, ‘笔’, ‘纸巾’, ‘胶带’, ‘湿巾’, ‘水彩笔’, ‘打火机’, ‘防碎气泡膜’, ‘榴莲壳’, ‘睫毛膏’, ‘眼影’, ‘仓鼠浴沙’, ‘大骨棒’, ‘旧毛巾’, ‘竹制品’, ‘粉笔’, ‘一次性口罩’, ‘一次性手套’, ‘粉底液’, ‘灰土’, ‘尼龙制品’, ‘尿片’, ‘雨伞’, ‘带胶制品’, ‘牙膏皮’, ‘狗尿布’, ‘椰子壳’, ‘粉扑’, ‘破碗碟’, ‘陶瓷’, ‘卫生纸’, ‘烟头’, ‘假睫毛’, ‘猫砂’, ‘牙刷’, ‘玉米棒’]
Read annotations
1 | train_labels['annotations'] |
1 | out:[{'area': 81909.20209190401, |
1 | type(train_labels['annotations']) |
As an example, let’s load an image and its annotation.
1 | n = random.randint(1, len(train_labels['annotations'])) # select the random n-th image as example |

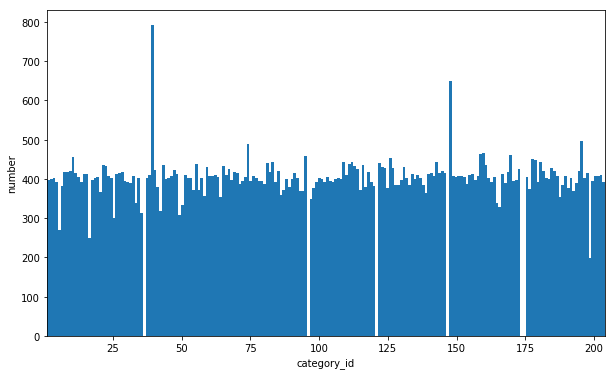
Observe the distribution of classes.
1 | image_ids = [] |
1 | plt.figure(figsize=(10, 6)) |
Convert annotations into CSV format
1 | with open('./dataset/resizedFullGarbageDataset/train.csv','w') as f: |
05.2.Train a garbage classifier
1 | from __future__ import absolute_import, division, print_function, unicode_literals |
Import dataset and preprocessing
Because our dataset is a bit large, RAM may not be enough to directly load all images. We can use flow_from_dataframe to load our dataset. (click here to read more about this function)
First, load labels from our .csv file. We use pandas.read_csv, it loads csv file to DataFrame format.
1 | df=pd.read_csv("./dataset/resizedFullGarbageDataset/train.csv", encoding='gbk', dtype=str) |
| id | label | name | filename | |
|---|---|---|---|---|
| 0 | 11003 | 2 | 核桃 | 11003.jpg |
| 1 | 11004 | 2 | 核桃 | 11004.jpg |
| 2 | 11005 | 2 | 核桃 | 11005.jpg |
| 3 | 11006 | 2 | 核桃 | 11006.jpg |
| … | …… | …… | …… | …… |
Then, use keras.preprocessing.image.ImageDataGenerator to load trainset.
‘catagories’ in the JSON file says, the dataset contains 202 classes, but actually it has only 198 classes. To avoid confusing df['label'] with index of classifier output, we use df['name'] as input.
75% of images are set as trainset, while 25% of images are set as testset.
1 | batch_size = 32 |
Correspondingly, we can use .class_indices to see the relationship between name and index before one-hot encoding.
1 | names = trainset.class_indices |
1 | {'KT板': 0, |
We can define a function to get name through index.
1 | def getname(index): |
trainset[i] has two parts. trainset[i][0] is the i-th batch of image, while trainset[i][1] is one-hot encodings which represents classes.
1 | plt.figure(figsize=(16,6)) |
Describe our model
As an example, we describe the following model.
(This example may not have good performance.)
1 | input_shape = (sizeX, sizeY, 3) |
Start learning
Because the dataset is large, it may take a very long time.
1 | STEP_SIZE_TRAIN=trainset.n//trainset.batch_size |
Evaluate the model
1 | model.evaluate_generator(testset,verbose=1) #predict |
Save the trained model
1 | modelname = 'garbageExample0' |
05.3.Make prediction on validationset
from future import absolute_import, division, print_function, unicode_literals
TensorFlow and tf.keras
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import backend as K
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.callbacks import LearningRateScheduler
from tensorflow.keras.preprocessing import image
Helper libraries
1 | import numpy as np |
Load trained model
1 | modelname = 'garbageExample0' |
Import validationset
1 | valiset_path = './dataset/resizedFullGarbageDataset/val_resized' |
Define getname() function
The names is in the order generated by flow_from_dataframe before training.
1 | names = {'KT板': 0, 'PVC管': 1, 'X光片': 2, '一次性口罩': 3, '一次性塑料餐盒餐具': 4, '一次性手套': 5, |
Define get_category_id() function
1 | with open('./dataset/resizedFullGarbageDataset/train.json', 'r', encoding='utf-8') as f: |
Make prediction and post process
1 | results_name = [] |
Observe random 20 images
1 | randNums = random.sample(range(0, len(valiset_filenames)), 20) |

Save results
1 | resultName = 'test0' |