CNN-based Handwritten Digit Recognition
1 | from __future__ import absolute_import, division, print_function, unicode_literals |
Import MNIST dataset
This guide uses the MNIST dataset which contains 70,000 grayscale images in 10 categories. MNIST stands for Mixed National Institute of Standards and Technology database.
The MNIST dataset is often used as the “Hello, World” of machine learning programs for computer vision. It contains images of handwritten digits (0, 1, 2, etc.).
Here, 60,000 images are used to train the network and 10,000 images to evaluate how accurately the network learned to classify images. You can access MNIST directly from TensorFlow. Import and load MNIST data directly from TensorFlow:
1 | mnist = keras.datasets.mnist |
Explore the data
Let’s explore the format of the dataset before training the model. The following shows there are 60,000 images in the training set, with each image represented as 28 x 28 pixels:
1 | train_images.shape |
1 | #Likewise, there are 60,000 labels in the training set: |
1 | #Each label is an integer between 0 and 9: |
1 | #Each label is an integer between 0 and 9: |
1 | #And the test set contains 10,000 images labels: |
Preprocess the data
The data must be preprocessed before training the network. If you inspect the first image in the training set, you will see that the pixel values fall in the range of 0 to 255:
1 | plt.figure() |
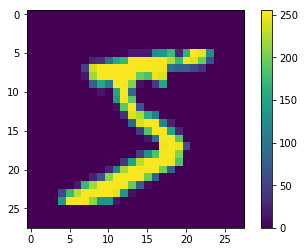
Scale these values to a range of 0 to 1 before feeding them to the neural network model. To do so, divide the values by 255. It’s important that the training set and the testing set be preprocessed in the same way.
In addition, encode labels using one-hot encoding.
1 | train_images_normed = train_images / 255.0 #make the value between 1 and 0 |
To verify that the data is in the correct format and that you’re ready to build and train the network, let’s display the first 25 images from the training set and display the class name below each image.
1 | plt.figure(figsize=(10,10)) |

Build the model
Building the neural network requires configuring the layers of the model, then compiling the model.
This example is LeNet-5, you can modify the model as you like.
1 | model = keras.Sequential([ |
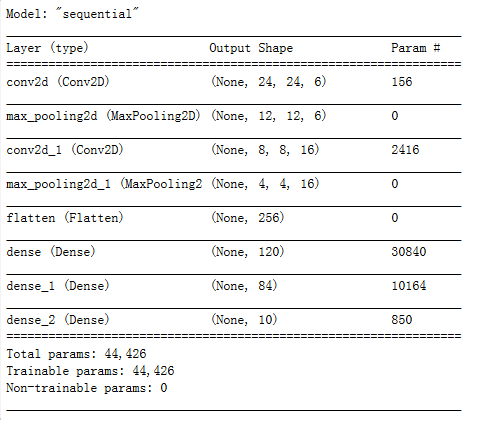
Observe the summary.
1 | model.summary() |
Define the process you train the model.
1 | model.compile(loss=keras.losses.categorical_crossentropy, |
Train the model
Feed the model
To start training, call the model.fit method—so called because it “fits” the model to the training data:
1 | model.fit(train_images_normed, train_labels_onehot, batch_size=100, epochs=6) |
As the model trains, the loss and accuracy metrics are displayed.
Evaluate accuracy
Next, compare how the model performs on the test dataset:
1 | test_loss, test_acc = model.evaluate(test_images_normed, test_labels_onehot, verbose=2) |
Make predictions
1 | predictions = model.predict(test_images_normed) |
Here, the model has predicted the label for each image in the testing set. Let’s take a look at the first prediction:
1 | predictions[0] |
A prediction is an array of 10 numbers. They represent the model’s “confidence” that the image corresponds to each of the 10 different articles of clothing. You can see which label has the highest confidence value:
1 | np.argmax(predictions[0]) |
So, the model is most confident that this image is 7. Examining the test label shows that this classification is correct:
1 | test_labels[0] |
Graph this to look at the full set of 10 class predictions.
1 | def plot_image(i, predictions_array, true_label, img): |
Verify predictions
With the model trained, you can use it to make predictions about some images.
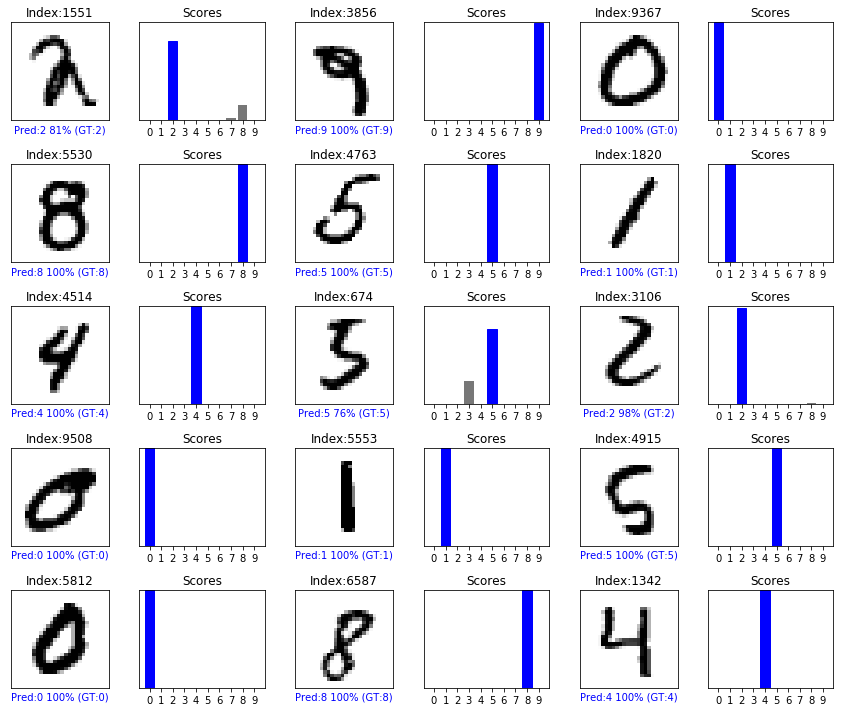
Let’s look at the 0th image, predictions, and prediction array. Correct prediction labels are blue and incorrect prediction labels are red. The number gives the percentage (out of 100) for the predicted label.
1 | i = 0 |

1 | i = 12 |

Let’s plot several images with their predictions. Note that the model can be wrong even when very confident.
1 | # Plot random 25 test images, their predicted labels, and the true labels. |