Pandas Introduction 4
accumulation
| count() | 计数项 |
|---|---|
| first()、last() | 第一项与最后一项 |
| mean()、median() | 均值与中位数 |
| min()、max() | 最小值与最大值 |
| std()、var() | 标准差与方差 |
| mad() | 均值绝对偏差(mean absolute deviation) |
| prod() | 所有项乘积 |
| sum() | 所有项求和 |
| describe() | 分析数据的所有特征(如最大值) |
| dropna() | 丢失有缺失值的行 |
GroupBy
分割,应用,组合
separate,accumulate,combine
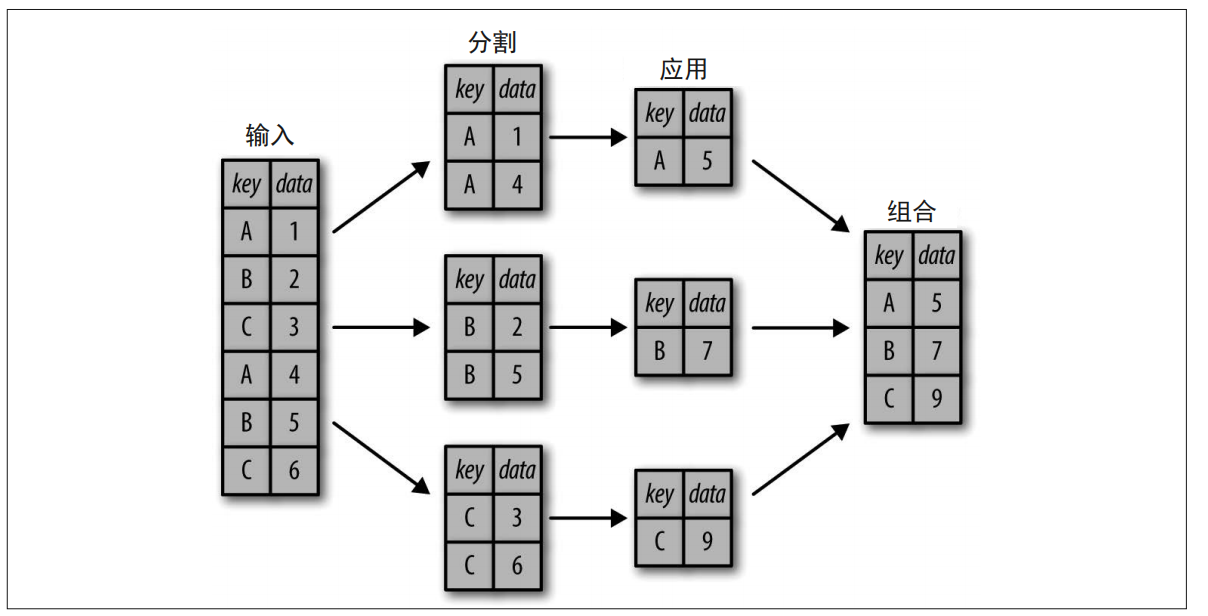
中间过程不需要被看见
1 | df = pd.DataFrame({'key': ['A', 'B', 'C', 'A', 'B', 'C'], 'data': range(6)}, columns=['key', 'data']) |
行星案例:
1 | import seaborn as sns |
累计、过滤、转换和应用
aggregate()、filter()、transform() 和 apply()
1 | rng = np.random.RandomState(0) |
可自定义的键:
1 | L = [0, 1, 0, 1, 2, 0] |
数据透析表
pivot_table
1 | titanic.groupby(['sex','class'])['survived'].aggregate('mean').unstack() |
can be replaced by:
1 | titanic.pivot_table('survived',index='sex',columns='class') |
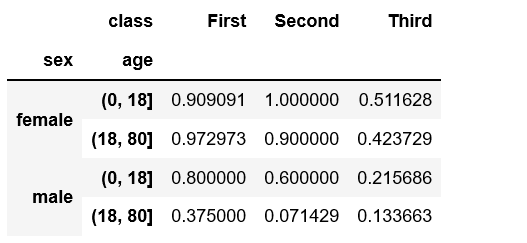
we can use cut and qcut to separate the table
cut can be used to add one more index
1 | age=pd.cut(titanic['age'],[0,18,80]) |
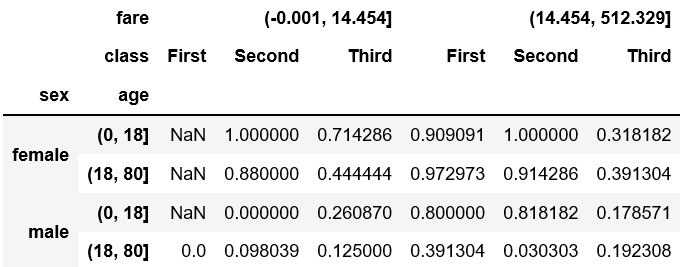
qcut can be used to add one more table
1 | fare=pd.qcut(titanic['fare'],2) |
full pivot_table tags:
1 | DataFrame.pivot_table(data, values=None, index=None, columns=None, |