《算法图解》Grokking Algorithms (2)
第四章 快速排序
divide and conquer(D&C)算法
递归式问题解决方法
理解:
用D&C解决:1)找出基线条件;2)不断分解问题,直到符合
农场主分地,1680m*640m,要求均匀分成正方形,且尽可能大
即一边的长度是另一边的整数倍
在1680640中,1680=640\2+400
即可用640400计算—>问题缩小了 (适用于小块地最大方块也适用于整块第的最大方块—*欧几里得算法**)
下面为:640=400+240—>240*400
400=240+160—>160*240
240=160+80—>80*160
160=80*2—>找到了
代码示例:
简单的数列求和:
1 | def sum(arr): |
递归法:
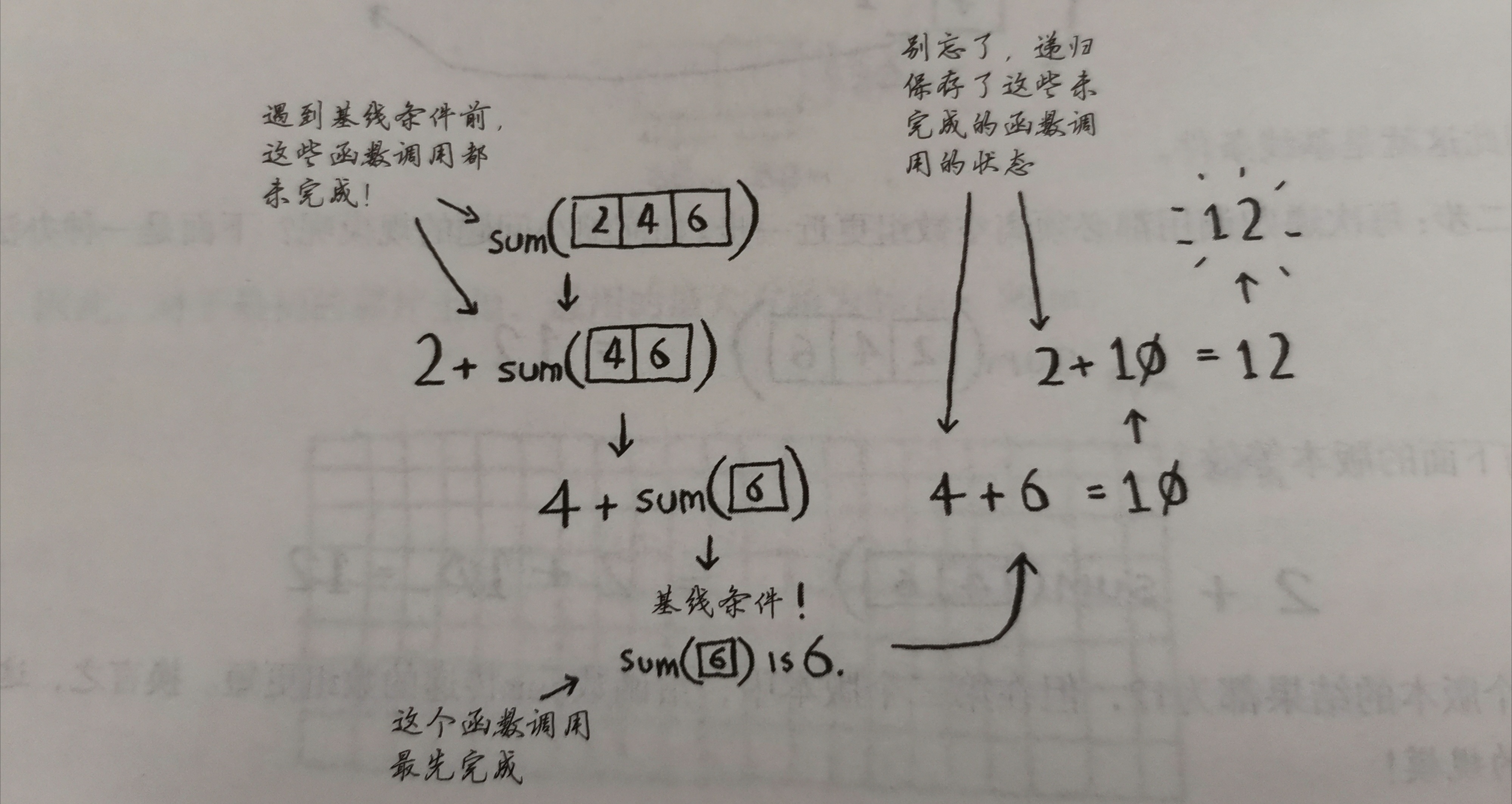
找出基线条件:数组不包含元素或只包含一个元素,计算总和很简单,如数组没有元素,和为0,这就是基线条件
每次递归都要离空数组近一步(缩小问题规模):
sum(2,4,6)=12 —> 2+sum(4,6)=2+10=12
1 | #连续数字求和 |
快速排序
c语言标准库中的函数gsort就是快速递归
将一个无序的列表排序:将第一个书局当做基准值,将小于它的放前面,大于它的放后面,如:
33,15,10—>(15,10)(33)()
这被称为分区(partitioning)
现在有三个组,再分别将小于和大于基准值的子数组用相同的方法排序
代码示例:
1 | def quicksort(array): |
大O表示法
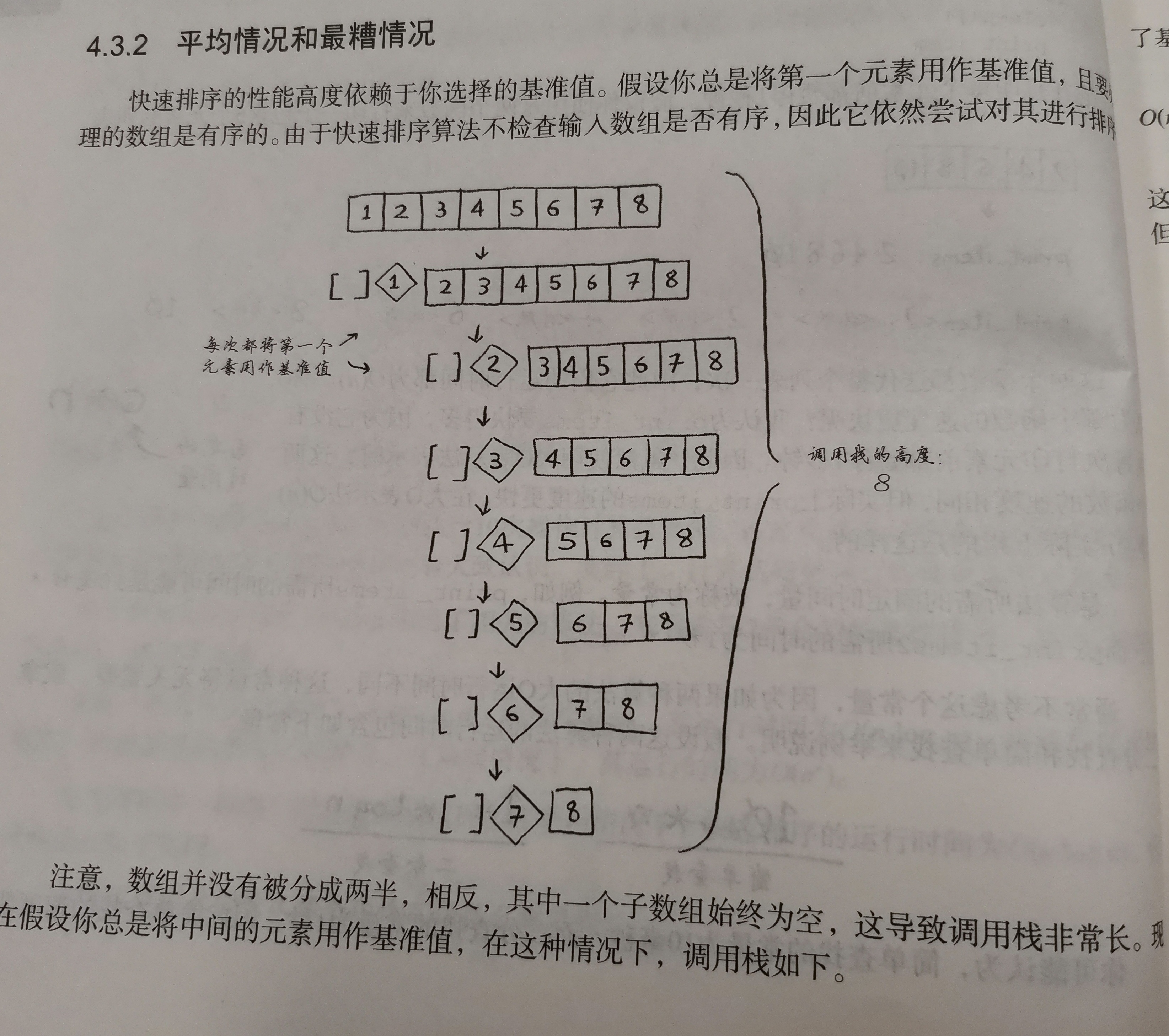
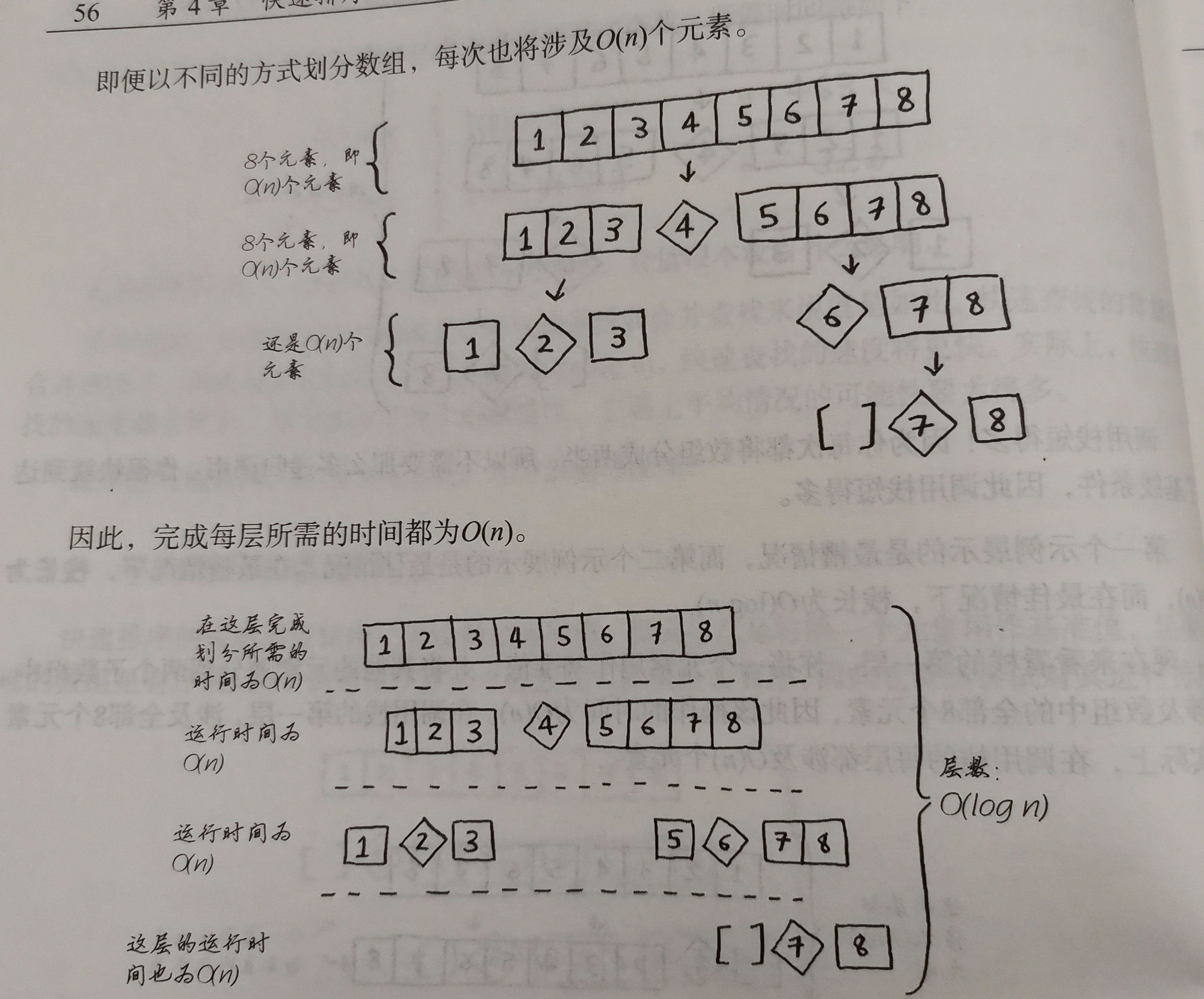
快速排序速度取决于基准值,速度可以等于合并排序(merge sort),时间为O(nlogn),但糟糕的情况可能跟选择排序(O(n^2))相同。
比较合并排序与快速排序
1 | def print_items(list): |
两者的大O相同,虽然两者运行时间不同
其中的10毫秒和1秒为c(常数,固定时间)
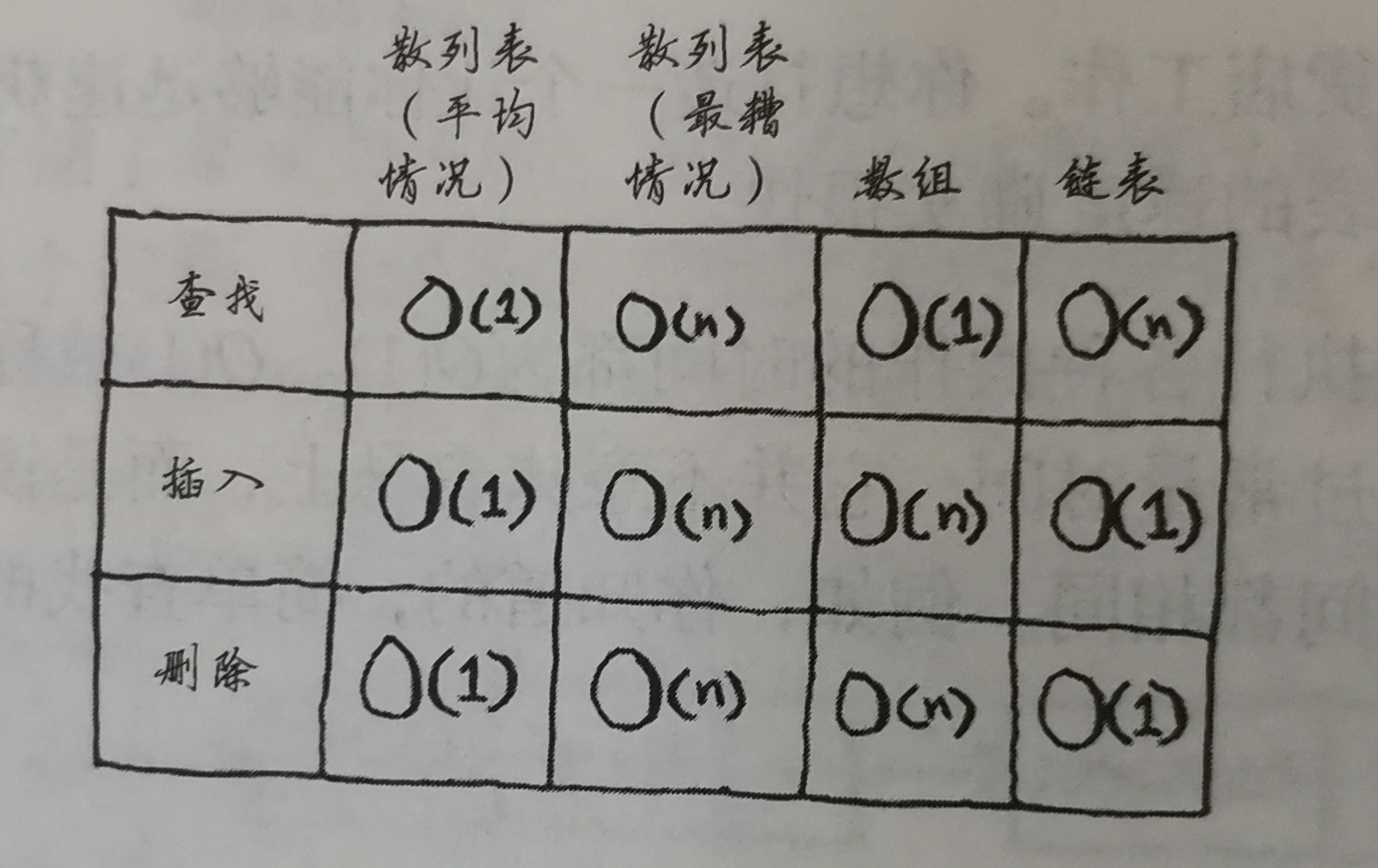
平均情况和最糟情况
第五章 散列表
是什么
在商店的价目表查询商品价格:
无序价目表:简单法(第一章)O=O(n)
按字母顺序排:二分法(第一章) O=O(log2n)
但是店员却能背下价目表,在提及商品时瞬间找到价格:

实现这一点需要散数列
散数列:将输入映射到数字
满足要求:必须一致:当输入一样时输出也必须一样
不同的输入映射到不同的数字:输入不同时输出也不同
==>数学的one to one 函数
步骤:
创建空数组
填写数组:将apple设置为3,则3的元素填写苹果的价格(以此类推)
有用原因:
1.相同输入映射相同索引
2.不同输入映射不同索引
3.散数列知道数组有多大,只映射有效值
可以用字典实现:
1 | book=dict() |
实际应用
电话簿查询
网址查询(转为IP地址):Google.com->74.125.239.133(DNS resolution)
防止重复
在投票时,判断这个人是否已经投过票
设置一个字典,将投过票的人放入字典:
1 | voted={} |
如果tom投过票就会出现在这个字典中。返回值为true,否则为false
如果为false(不在列表里)
1 | voted={} |
将散列表用作缓存
网站的缓存
访问网页:(拿百度举例)
- 向百度服务器发出请求
- 服务器处理,生成网页发给你
- 你获得网页
推荐功能:
获取你最近的足迹,推荐你可能感兴趣的内容,即在第二步进行一些运算
但这个过程可能需要几秒,并且它的用户千千万,所花费时间较长。
于是你觉得加载慢,于是你会觉得百度慢、百度这个软件不好
解决:
比如家里一个孩子很喜欢星球,总问你火星离地球多远?月球呢?… …
每次你又要上网搜,在说出答案,这需要花时间,就跟之前网站服务器在第二步运算的时间一样
但问多了你就能记住,月球离地球238,900英里这个答案
下次他再问你你就不需要查
好处:
时间短
网页服务器工作量少
这些缓存就存在散列表中(如主页,about等)(历史记录或者网站缓存里)
实现代码:
1 | cache={} #h缓存的散列表 |
这样也可以解释为什么我们第一次访问一个网站的时候要花几秒,但我们访问常用的较大的网站,如百度主页,就会瞬间完成
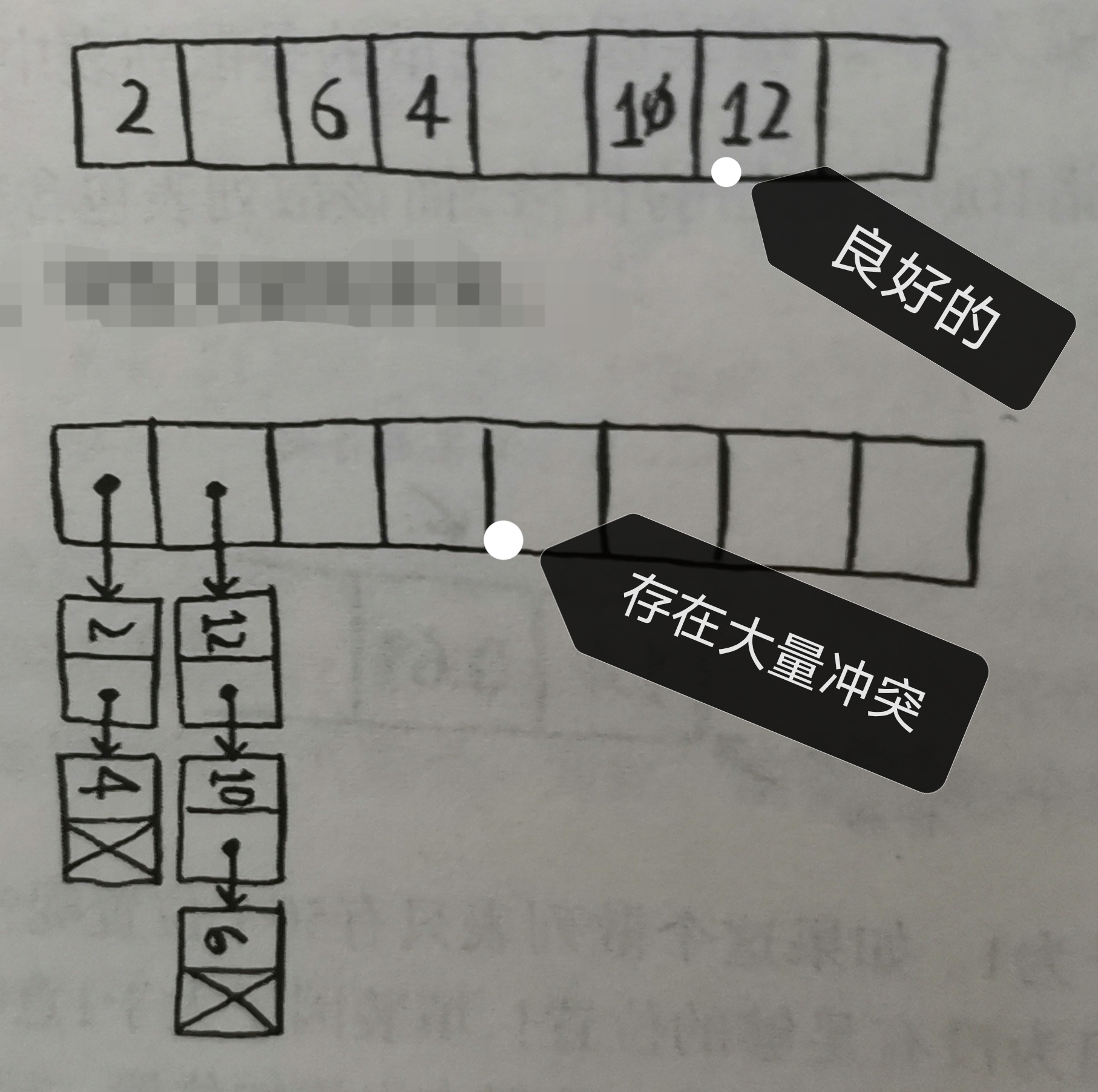
冲突
散列表要做到不同输入映射到数组的不同位置几乎是无法完成的
比如:
将价目表按字母顺序放进散列表:

apple放进第一个,banana放进第二个,但遇到avocado的时候,发现它的首字母也是a
这个时候,覆盖apple,下次查询apple的价格时查到的是avocado(因为这个是数组而不是链表,无法直接在中间加值)
解决方法:在a的位置储存一个链表,将a开头的都放进链表里,但这将使速度减慢
但是,假设这个商店只销售a开头的商品,数组的第一位将特别长,但后面25位将被浪费
需要合理安排散列函数,均匀分配
性能
平均情况:均匀分配列表,获得数组的查找效率和链表的插入删除效率
最糟情况:出现严重冲突,获得数组和链表的缺点
获得平均情况:较低的填装因子,良好的散列函数
填装因子
填装因子=列表包含元素量÷位置总数
如果元素量大于总位数(即需要链表),填装因子大于1,就需要增加数列长度(创建一个新的数列,用hash函数将旧数列的元素装到新数列里),一般填装因子超过0.7就需要调整数列。
良好的散列函数
即均匀排布
第六章 广度优先搜索
即找出两样东西之间的最短距离(不一定是指长度上的距离)
图简介
从双子峰做公交去金门大桥:
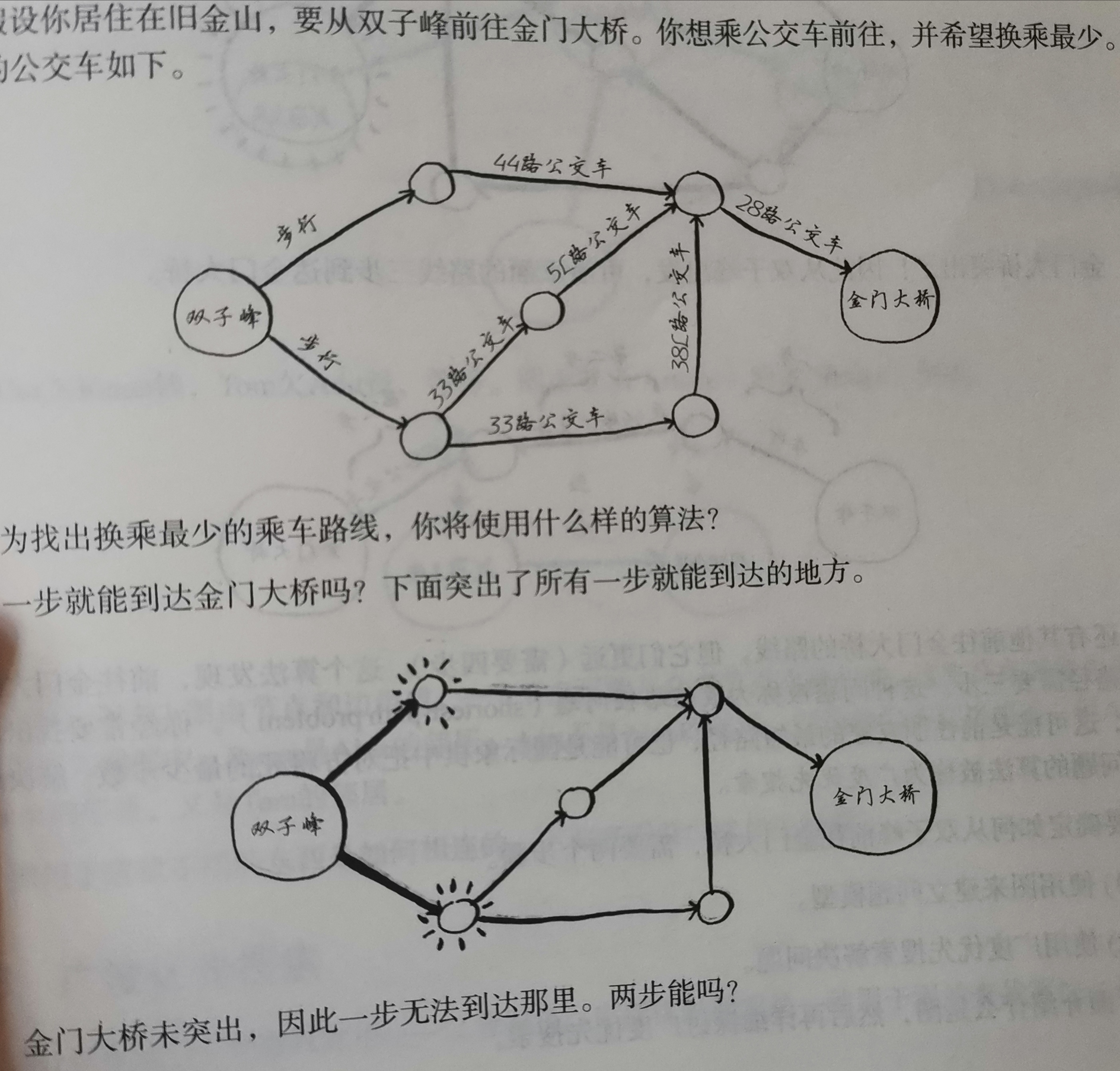
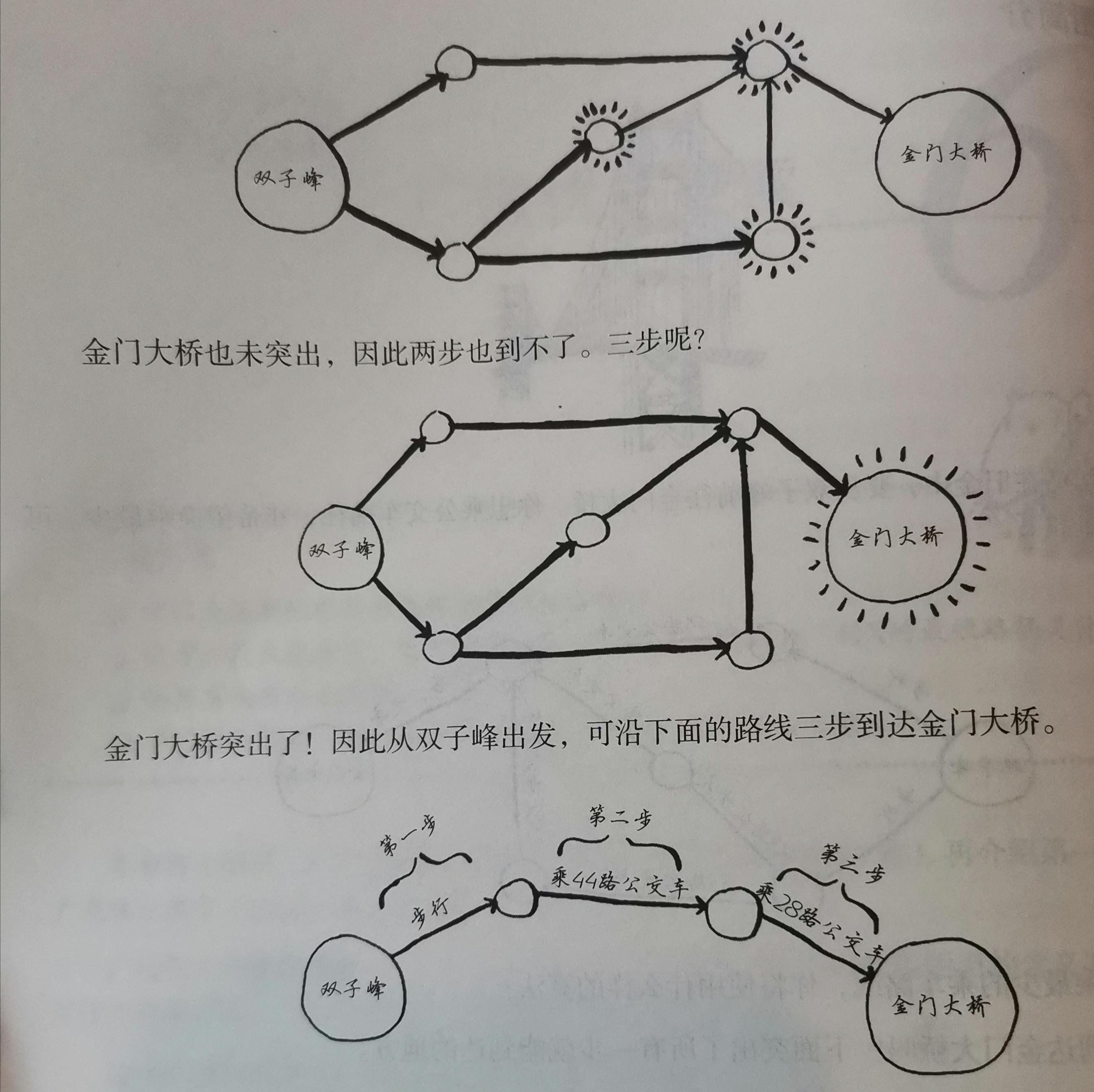
各种地图软件就是这么实现的
图是什么
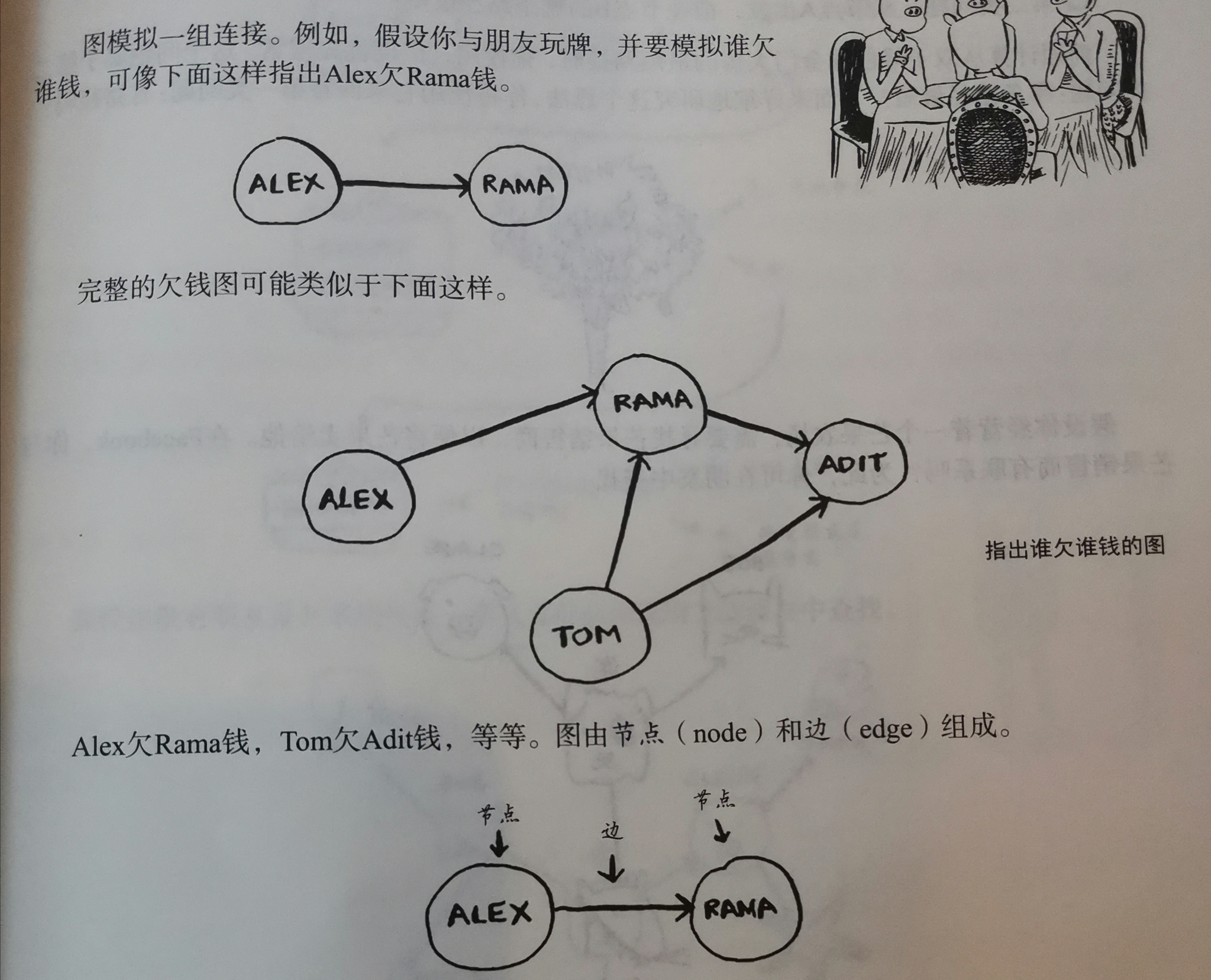
即关系网
广度优先搜索
可解决问题:
- 从A出发有前往B的路径吗?
- 从A出发前往B哪条路最短?
从双子峰去金门大桥的问题即第二个问题
第一个问题:
你有一个农场,你需要一个销售商将商品售卖到市场上
你需要在你的朋友中找有没有销售商
创建朋友名单,再依次检查是否有销售商
但如果你的朋友中没有销售商,你需要在朋友的朋友中找销售商检查每个人时,要将他的朋友加入名单
搜遍你的人际圈直到找到销售商就是广度优先搜索
查找最短路径
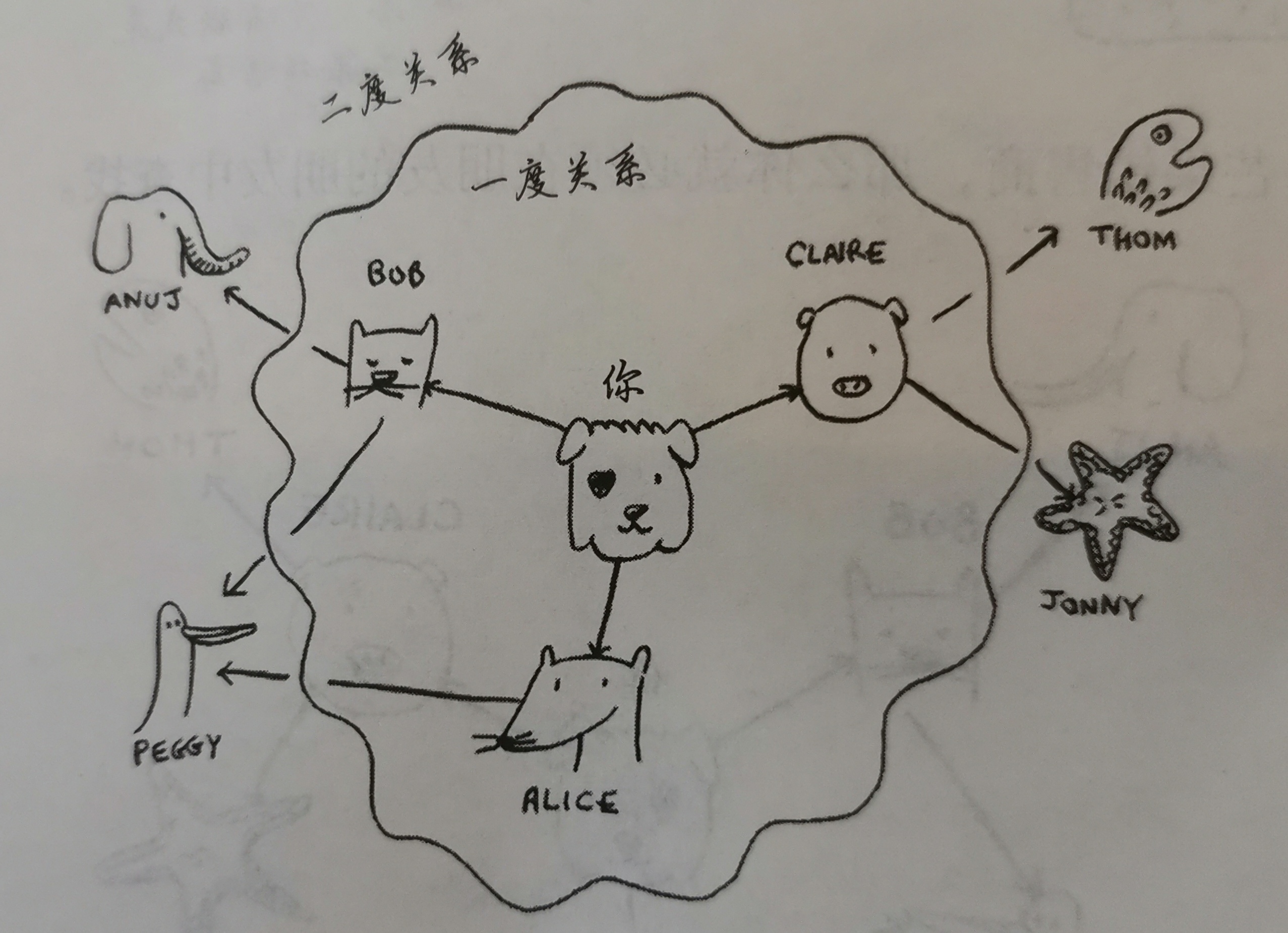
第二个问题:谁是关系最近的销售商
第一层关系肯定大于第二层,第二层肯定大于第三层… …
广度优先搜索:先检查第一层关系,全部检查完再检查第二层关系
所以,这不仅是找到路径,还是找到最短路径
这样查找时必须按顺序排名单

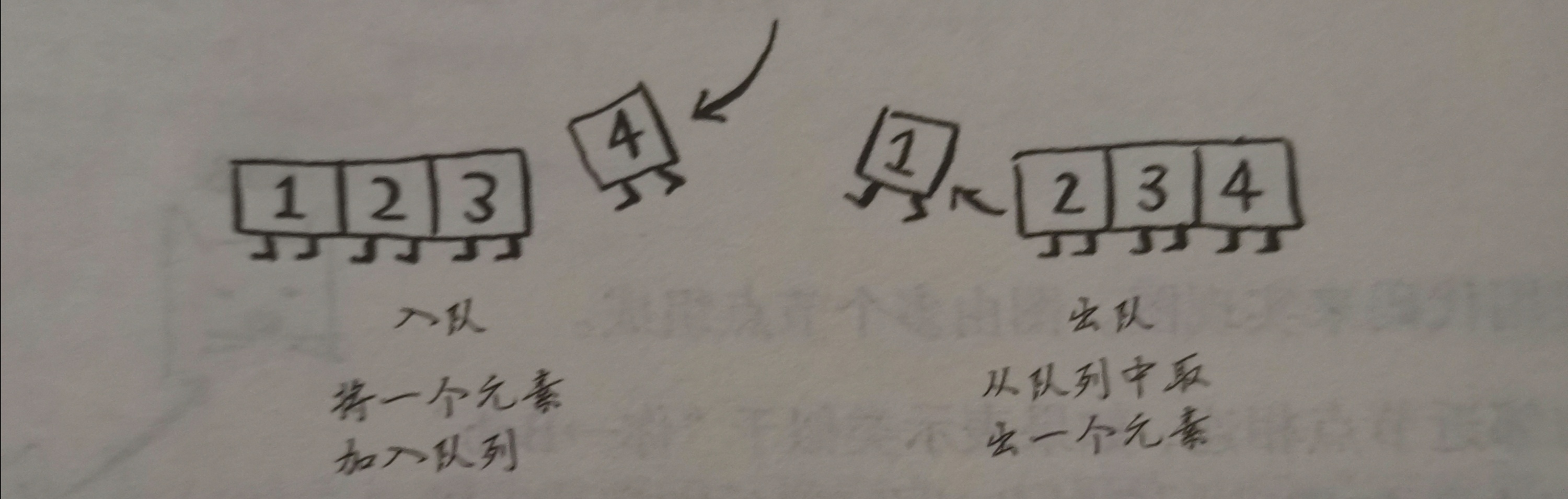
队列
入列和出列

实现图
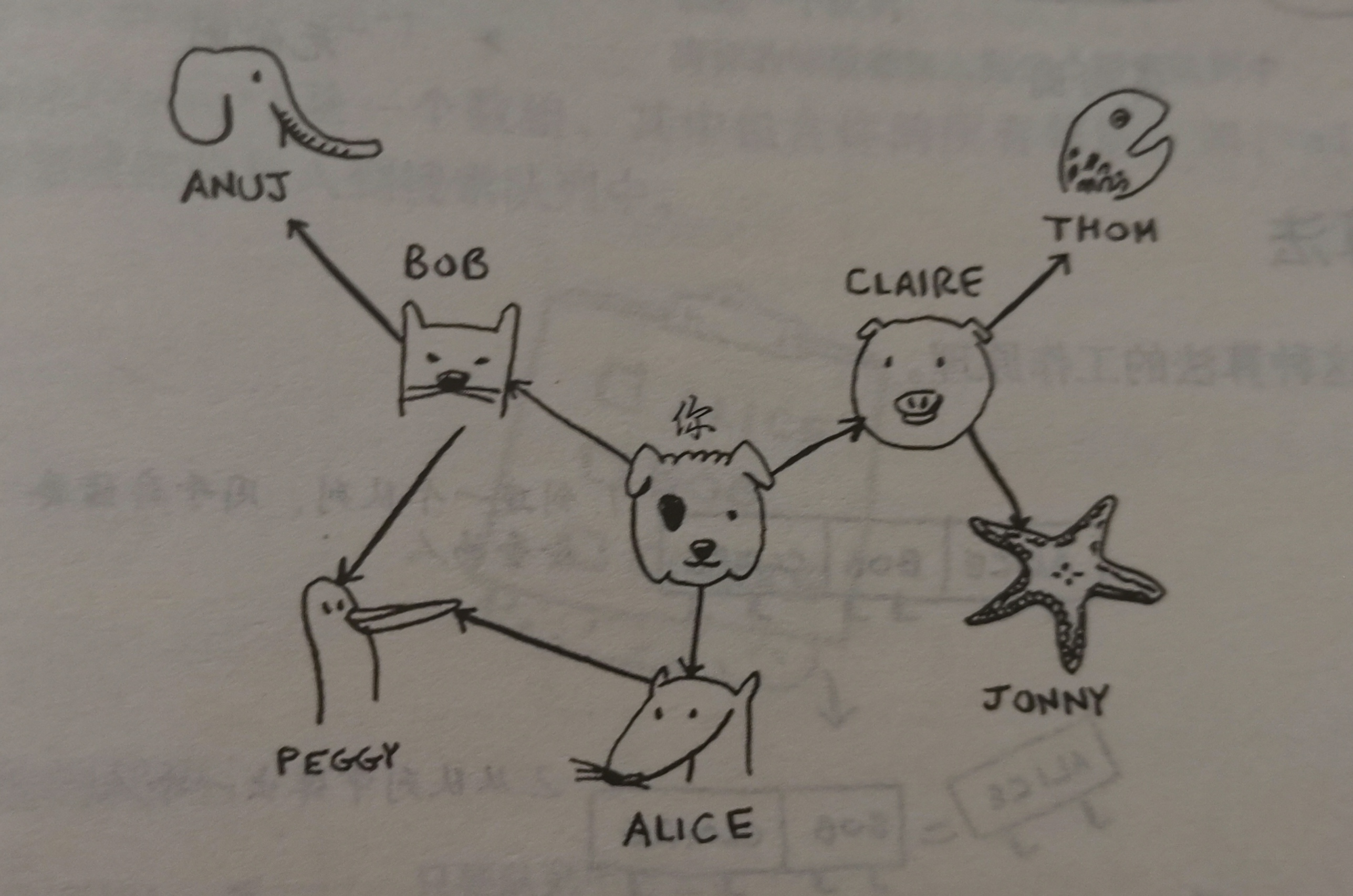
此关系可表示为:
1 | graph={} |
其中代码顺序变化是无所谓的,因为散列表是无序的
这幅图中出现了有向图与无向图:
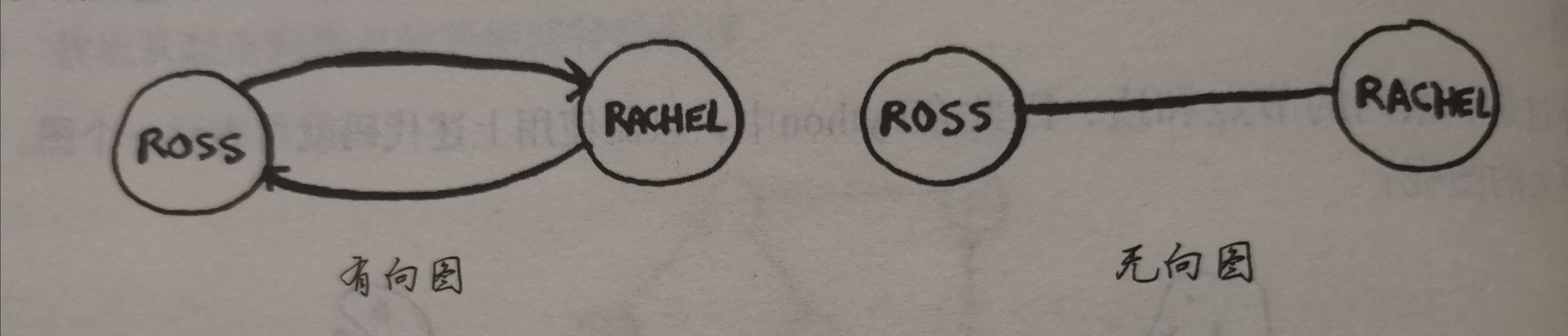
这两个是等价的
实现算法
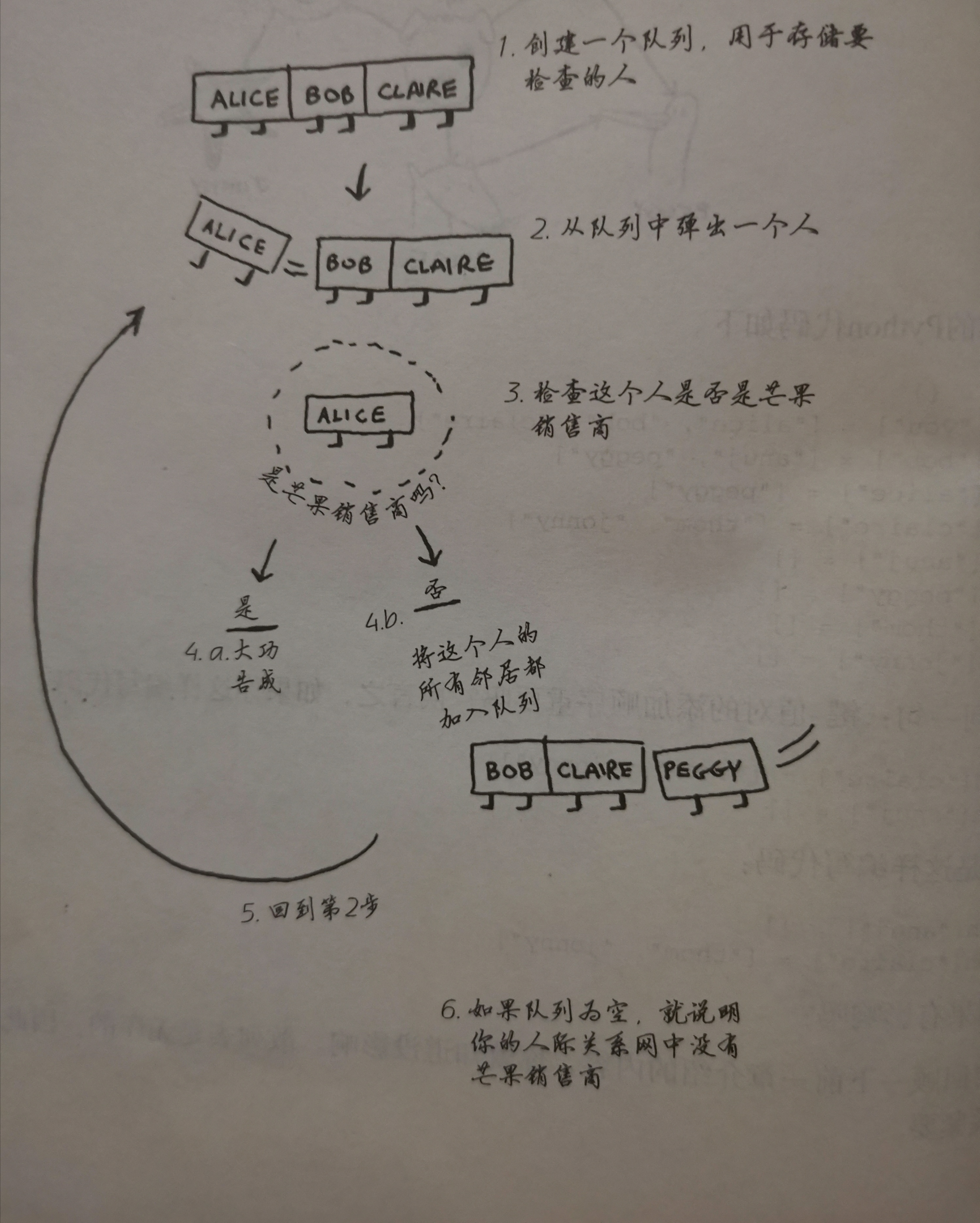
代码:利用deque函数
1 | from collections import deque |
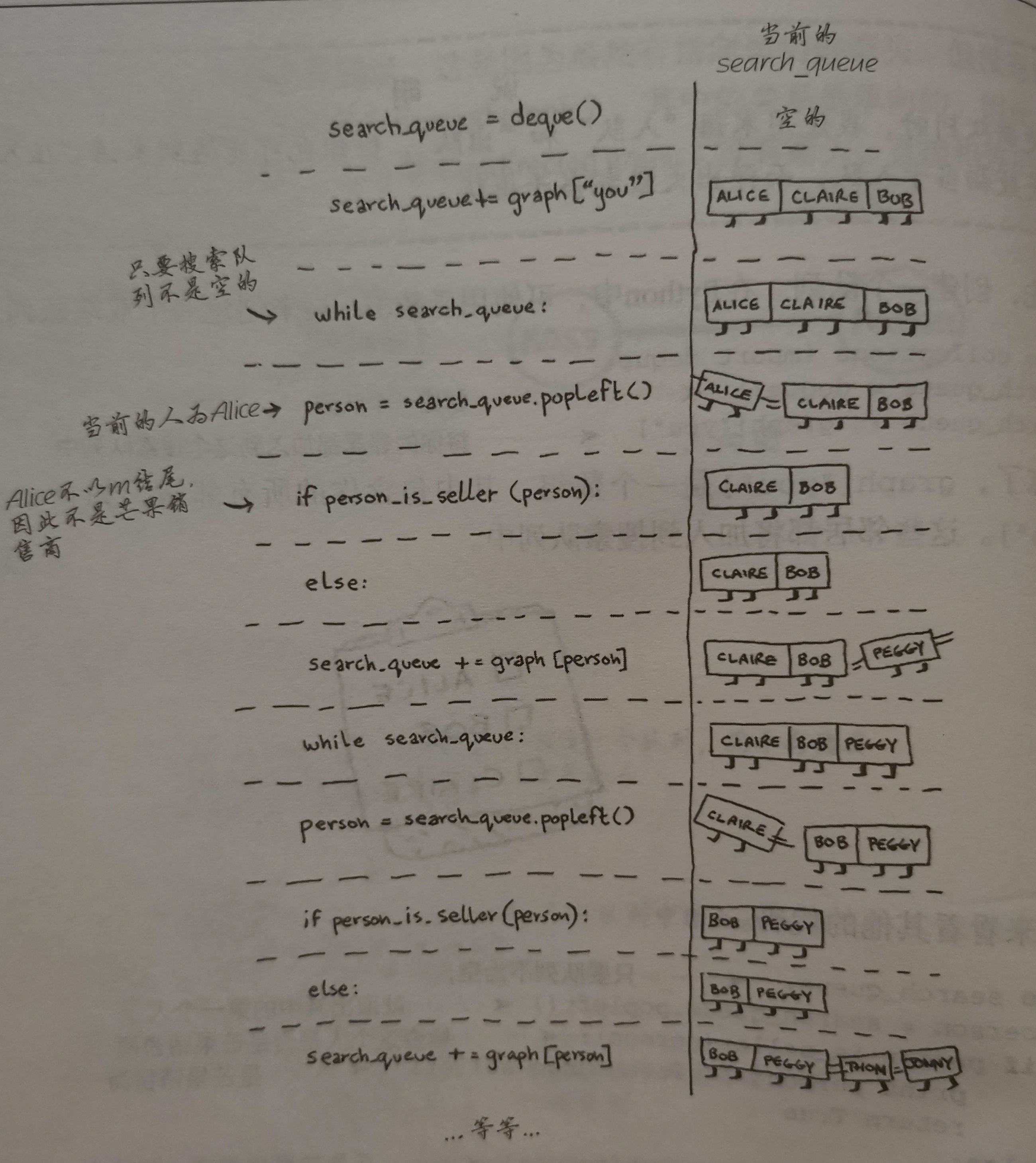
防止死循环出现:
当检查 you这个列表,找到peggy,peggy不是销售商,列出peggy的朋友,peggy的朋友是你,又检查you这个列表… …
所以我们需要加上:
1 | def search(name): |
运行时间
O=O(人数+边数) (可写为O(V+E))